بسم الله الرحمن الرحيم
01 الفصل الأول: مقدمة عن التعلم العميق ومكتبة PyTorch
تاريخ النشر : Dec. 13, 2023
None
Welcome to the first part of this book. This is where we’ll take our first
steps with PyTorch, gaining the fundamental skills needed to understand its
anatomy and work out the mechanics of a PyTorch project.
In chapter 1, we’ll make our first contact with PyTorch, understand what it is and what problems it solves, and how it relates to other deep learning frameworks.
سنتعلم من هذا الفصل :
- لماذا نغير واجهتنا من التعلم الالي إلي التعلم العميق.
- لماذا تلعب مكتبة PyTorch دور حيوي في هذا المجال
- معرفة أمثلة لمشاريع التعلم العميق .
- عتاد الكمبيوتر المطلوب لأنجاز أمثلة الكتاب
يغطي مصطلح الذكاء الاصطناعي مجموعة من التخصصات التي تسبب الارتباك للكثيرين وإثارة الخوف لدي بعضهم. من الخداع التأكيد على أن آلات اليوم تتعلم كيفية "التفكير" بأي بُعد إنسان, ولكن دعنا نقول اننا اكتشفنا فئة من الخوارزميات العامة القادرة على القيام بالعمليات المعقدة وغير الخطية بشكل فعال للغاية، والتي يمكننا استخدامها لأتمتة المهام التي كانت مقتصرة في السابق على البشر.
تندرج هذه الفئة العامة من الخوارزميات التي نتحدث عنها ضمن فئة التعلم العميق كأحد فروع الذكاء الاصطناعي، والتي تتعامل مع تدريب الكيانات الرياضية المسماة الشبكات العصبية العميقة deep neural networks من خلال تقديم أمثلة مفيدة.
يستخدم التعلم العميق كميات كبيرة من البيانات لإنجاز الوظائف المعقدة التي تكون مدخلاتها ومخرجاتها متباعدة،
مثل ادخال مجموعة من الصور ، ويكون المخرجات وصف كتابي لهذة الصور , أو قد يكو المدخلات نص مكتوب فيُخرج كصوت طبيعي يقرأ النص ؛
يتيح لنا هذا النوع من القدرات إنشاء تطبيقات ذات وظائف كانت، حتى وقت قريب جدًا، حكرًا على البشر حصريًا.
ثورة التعلم العميق
ولتقدير الثر الكبير الذي أحدثه نهج التعلم العميق ، دعونا نرجع خطوة إلى الوراء للحصول على القليل من المنظور. حتى العقد الماضي، كانت الفئة الأوسع من الأنظمة التي تندرج تحت عنوان التعلم الآلي machine learning تعتمد بشكل كبير على هندسة الميزات feature engineering. الميزات هي تحويلات تُجري على البيانات المدخلة الي الخوارزمية النهائية، مثل المصنف، بغرض التسهيل لإنتاج نتائج صحيحة على البيانات الجديدة . تتكون هندسة الميزات من التوصل إلى التحويلات الصحيحة حتى تتمكن الخوارزمية النهائية من حل المهمة.
على سبيل المثال، من أجل التمييز بين الآحاد والأصفار في صور الأرقام المكتوبة بخط اليد، سنتوصل إلى مجموعة من المرشحات لتقدير اتجاه الحواف فوق الصورة، ثم تدريب أحد المصنفين على التنبؤ بالرقم الصحيح في ضوء توزيع الحواف الاتجاهات. ميزة أخرى مفيدة يمكن أن تكون عدد الثقوب المغلقة، كما هو موضح في الصفر، والثمانية، وعلى وجه الخصوص، الاثنين المتعرجين.
PyTorch for deep learning
1.2 مكتبة PyTorch للتعلم العميق
كُتبة مكتبة PyTorch بلغة البايثون Python , وروعي في فيها تسهيل بناء مشاريع التعلم العميق, والتزم فيها نهج معاير Python.
فبنية PyTorch الواضحة وواجهة برمجة التطبيقاتAPIs المبسطة وسهولة تصحيح الأخطاء debugging تجعلها خيارًا ممتازًا لتبسيط تعلم مناهج التعلم العميق, وبلإضافة إلي ذاللك أثبتت PyTorch أنها مؤهلة للاستخدام في السياقات المهنية للأعمال التجارية رفيعة المستوى, هذة الدعائم جعلتها المكتبة المفضلة لدي الكثييرين, و أضحت واحدة من أهم أدوات التعلم العميق في كثير من التطبيقات.
تعد ألية التعلم العميق وظيفة رياضية معقدة إلى حد ما تقوم ببناء المخرجات بناء علي المدخلات. ولتسهيل التعبير عن هذه الوظيفة، توفر PyTorch بنية بيانات أساسية، tensor، وهو عبارة عن مصفوفة متعددة الأبعاد تشترك في العديد من أوجه التشابه مع مصفوفات NumPy. لذالك يأتي PyTorch مزودًا بميزات لإجراء عمليات حسابية متسارعة على أجهزة مخصصة، مما يجعل من السهل تصميم بنيات الشبكات العصبية وتدريبها على أجهزة فردية أو موارد حوسبة متوازية.
يهدف هذا الكتاب إلى أن يكون نقطة انطلاق لمهندسي البرمجيات وعلماء البيانات والطلاب المتحمسين الذين يجيدون لغة بايثون ليشعروا بالتمكن عند استخدام PyTorch لبناء مشاريع التعلم العميق. نريد أن يكون هذا الكتاب متاحًا ومفيدًا قدر الإمكان، ونتوقع أنك ستتعلم من المفاهيم الواردة في هذا الكتاب وتستطيع تطبيقها فى مجالات أخرى.
ولتحقيق هذه الغاية، نستخدم نهجًا عمليًا ونشجعك على تطبيق الأمثلة العمليةبقدر الإمكان. بحلول الوقت الذي ننتهي فيه من الكتاب، نتوقع منك أن تكون قادرًا على إنشاء مشروع تعليمي عميق باستخدامه مصادر البيانات المختلفة.
على الرغم من أننا نؤكد على أهمية الجوانب العملية لبناء أنظمة التعلم العميق باستخدام PyTorch، إلا أننا نعتقد أن توفير مقدمة تأسيسية سهلة لأداة التعلم العميق مهم لاكتساب مهاراتك الجديدة.
يالها من خطوة نحو تزويد جيل جديد من العلماء والمهندسين وكذاللك الممارسين منشتي التخصصات بالمعرفة العملية اللازمة والتي ستكون العمود الفقري للعديد من مشاريع البرمجيات خلال العقود القادمة.
للحصول على أقصى استفادة من هذا الكتاب، ستحتاج إلى أمرين:
- بعض الخبرة في البرمجة بلغة بايثون. ستحتاج إلى التعرف على Python data types, classes, floating-point numbers وما شابه.
- الرغبة في التعلم وصقلها بالممارسة .ولا تقلق سنبدأ من الأساسيات و إذا تابعت معنا الخطوات سيكون التعلم سهل عليك.
Deep Learning with PyTorch is organized in three distinct parts. Part 1 covers the foundations,
examining in detail the facilities PyTorch offers to put the sketch of deep learning
in figure 1.1 into action with code. Part 2 walks you through an end-to-end project
involving medical imaging: finding and classifying tumors in CT scans, building on
the basic concepts introduced in part 1, and adding more advanced topics. The short
part 3 rounds off the book with a tour of what PyTorch offers for deploying deep
learning models to production.
Deep learning is a huge space. In this book, we will be covering a tiny part of that
space: specifically, using PyTorch for smaller-scope classification and segmentation
projects, with image processing of 2D and 3D datasets used for most of the motivating
examples. This book focuses on practical PyTorch, with the aim of covering enough
ground to allow you to solve real-world machine learning problems, such as in vision,
with deep learning or explore new models as they pop up in research literature. Most,
if not all, of the latest publications related to deep learning research can be found in
the arXiV public preprint repository, hosted at https://arxiv.org.2
1.3 لماذاPyTorch؟
كما ذكرنا سابقًا، يُمكن لتعلم الآلة العميقة تنفيذ مجموعة واسعة من المهام المعقدة، مثل الترجمة الآلية، أو لعب الألعاب الاستراتيجية، أو حتى تحديد الأشياء في الصور المزدحمة، من خلال تدريب النموذج على أمثلة توضيحية.
ولتحقيق هذا عمليًا، نحتاج إلى أدوات مرنة يُمكن تكييفها مع مجموعة واسعة من المشكلات، وتكون فعّالة لتمكين التدريب على كميات كبيرة من البيانات في فترات زمنية معقولة. كما نحتاج إلى أن يُظهر النموذج المُدرَّب نتائج صحيحة في وجود تباين المُدخلات.
دعونا نلقي نظرة على بعض الأسباب التي دفعتنا إلى استخدام PyTorch.
1- السهولة : من السهل التوصية بـ PyTorch بسبب بساطته. يجد العديد من الباحثين والممارسين أنه من السهل تعلمه واستخدامه وتوسيعه وتصحيحه. إنه "بايثوني"، وعلى الرغم من أنه يتعلق بمجال معقد كأي مكتبة أخرى، إلا أنه يُوجد به مبادئ وأفضل ممارسات، مما يجعل استخدام المكتبة يبدو بشكل عام مألوفًا للمطورين الذين استخدموا بايثون سابقًا.
2- مميزات Tensor : وبشكل أكثر تحديدًا، فإن برمجة آلة التعلم العميق في PyTorch أمر طبيعي للغاية. يوفر لنا PyTorch نوع بيانات، Tensor، للاحتفاظ بالأرقام أو المتجهات أو المصفوفات بشكل عام. وبالإضافة إلى ذلك، يُوفِر وظائف للعمل عليها. يُمكننا البرمجة معها بشكل تدريجي، وإذا أردنا، بشكل تفاعلي، تمامًا كما نعتاد على ذلك في بايثون. إذا كنت تعرف NumPy، فإن هذا سيكون مألوفًا جدًا.
3 - سرعة الاداء: PyTorch تقدم شيئين يجعلانها ذات صلة خاصة بالتعلم العميق: أولاً، يوفر حسابًا سريعًا باستخدام وحدات المعالجة الرسومية (GPUs)، مما يؤدي غالبًا إلى سرعات تصل إلى 50 مرة أكثر من إجراء نفس الحساب باستخدام وحدة المعالجة المركزية (CPU). ثانيًا، توفر PyTorch مرافقًا تدعم التحسين العددي للتعبيرات الرياضية العامة numerical optimization on generic mathematical expressions، والتي يستخدمها التعلم العميق للتدريب. لاحظ أن كلتا الميزتين مفيدتان للحوسبة العلمية بشكل عام، وليس فقط للتعلم العميق. في الواقع، يُمكننا وصف PyTorch بأمان كمكتبة عالية الأداء مع دعم التحسين للحوسبة العلمية في بايثون.
4- محرك التصميم لـ PyTorch هو التعبير expressivity, ، مما يسمح للمطور بتنفيذ نماذج معقدة دون أن تفرض المكتبة تعقيدًا لا داعي له (إنه ليس إطار عمل!). يُمكن القول إن PyTorch يقدم واحدة من أكثر الترجمات سلاسة للأفكار إلى كود Python في مجال التعلم العميق. لهذا السبب، شهدت PyTorch اعتمادًا واسع النطاق في الأبحاث، كما يشهد على ذلك ارتفاع عدد الاستشهادات في المؤتمرات الدولية.
5- وتتميزPyTorch أيضًا بقدرتها على التنقل بسلاسة من مرحلة البحث والتطوير إلى مرحلة الإنتاج. على الرغم من أن التركيز كان في البداية على مجال البحث، تم تجهيز باي تورش ببيئة تشغيل C++ عالية الأداء يمكن استخدامها لنشر نماذج للاستدلال دون الحاجة إلى Python. كما يُمكن استخدامها لتصميم وتدريب النماذج في لغة البرمجة C++. كما وفرت روابط للغات أخرى وواجهة للنشر على الأجهزة المحمولة. تسمح لنا هذه الميزات بالاستفادة من مرونة بPyTorch واستخدام تطبيقاتنا حيث يكون من الصعب الحصول على وقت تشغيل كامل لـ Python أو قد يترتب عليها تكاليف باهظة.
1.3.1 المشهد التنافسي للتعلم العميق
لا شك أن إصدار PyTorch 0.1 في يناير2017 يُعتبر نقلة هامة من مرحلة أتسمت بتعدد المكتبات والأدوات والاطارات الخاصة بالتعلم العميق.الي مرحلة الدمج لهذة المكتبات والأدوات والاطارات والأغلفة وتنسيقات تبادل البيانات, فقد تحولت المجتمعات الفعّالة تدريجيًا إلى مؤيدين لإما PyTorch أو TensorFlow، مما أدى إلى تراجع شديد في استخدام المكتبات الأخرى، باستثناء تلك التي تُلبي احتياجات محددة. وفي هذا السياق:
- كانت Theano و TensorFlow في البداية من بين المكتبات الأولي ذات المستوى المنخفض، حيث كانت تتيح للمستخدم إعداد رسم بياني حسابي وتنفيذه.
- بينما Lasagne and Keras كانتا أغلفة عالية المستوى (high-level wrappers) حول Theano.
- تعددت المكتبات الأخرى مثل Caffe، وChainer، وDyNet، وTorch (الإصدار المُستند إلى Lua)، وMXNet، وCNTK، وDL4J في ملء مجالات متنوعة.
ثم شهدة الساحة تحولات جذرية، حيث اندمجت المجتمعات تقريبًا وراء إما PyTorch أو TensorFlow، مع تراجع الاهتمام بالمكتبات الأخرى، وهذا يأتي مع تغييرات ملحوظة:
- توقفت Theano، التي كانت إحدى أوائل أطُر التعلم العميق، عن التطوير النشط.
- حدث تطوير كبير في TensorFlow، حيث:
1- استُهلك Keras بالكامل ورُقِي إلى واجهة برمجة تطبيقات من الدرجة الأولى.
2- وتم توفير "eager mode" للتنفيذ الفوري،ليكون مشابها Pytorch
3- وأخيرًا تم إصدار TF 2.0 مع جعل "eager mode" افتراضيًا.
- كانت JAX من GOOGLE، التي تطورت بشكل مستقل عن TensorFlow، بدأت تكتسب شعبية كبيرة بفضل قدراتها المشابهة لـ NumPy مع دعم GPU وautograd وJIT.
- بينما PyTorch
1- استهلكت Caffe2 كواجهة خلفية
2- وقامت بتحسين العديد من السمات في بيئتها بأزالة low-level code المستخدم من مشروع Lua-based Torchز
3- وأصدرت إصدار 1.0 الذي جلب العديد من التطويرات، بالإضافة إلى إحلال CNTK وChainer بمكتبتين مُحدثتين ومُدعومتين.
على الرغم من نجاح TensorFlow في بناء خط أنابيب pipline قوي للإنتاج وجذب مجتمع واسع النطاق، إلا أن PyTorch حققت نجاحات كبيرة في مجال البحث ومجتمع التعليم، بفضل سهولة استخدامها، وقد اكتسبت زخمًا متزايدًا على مر الوقت، حيث يقوم الباحثون والطلاب بتدريب الطلاب والانتقال إلى الصناعة. ومن المثير أن يلاحظ أن PyTorch وTensorFlow بدأتا تتقاطعان مع بعضهما البعض من خلال عرض ميزاتهما وتعزيز تجربة المستخدم بشكل عام، وعلى الرغم من ذلك، فإن الفارق بينهما يظل واضحًا بطابعهما وطريقة تنفيذهما.
1.4 نظرة عامة على كيفية دعم PyTorch لمشاريع التعلم العميق
لنأخذ الآن بعض الوقت لإلقاء نظرة على خريطة عالية المستوى للمكونات الرئيسية التي تشكل PyTorch, يمكننا القيام بذلك بشكل أفضل من خلال النظر في ما يحتاجه مشروع التعلم العميق من PyTorch.
أولاً، تحتوي PyTorch على "Py" كما هو الحال في Python، ولكن يوجد بها الكثير من التعليمات البرمجية غير Python. في الواقع، لأسباب تتعلق بالأداء، معظم PyTorch مكتوب بلغة C++ وCUDA ، وهي لغة تشبه C++ من NVIDIA يمكن تجميعها لتعمل بتوازي هائل على وحدات معالجة الرسومات GPUs. هناك طرق لتشغيل PyTorch مباشرة من C++، وسننظر في تلك الطرق في الفصل 15. أحد دوافع هذه الإمكانية هو توفير استراتيجية موثوقة بتطبيق ونشر النماذج الذكية deploying models in production .
ومع ذلك، سنتفاعل في معظم الأوقات مع PyTorch من Python، ونبني النماذج، وندربها، ونستخدم النماذج المدربة لحل المشكلات الفعلية. في الواقع، فإن واجهة برمجة تطبيقات Python هي المكان الذي تتألق فيه PyTorch من حيث سهولة الاستخدام والتكامل مع نظام Python البيئي الأوسع. دعونا نلقي نظرة خاطفة على PyTorch.
كما تطرقنا بالفعل، PyTorch هي في جوهرها مكتبة توفر مصفوفات متعددة الأبعادmultidimensional arrays ، أو tensors بلغة PyTorch (سنتناوله بالتفصيل في الفصل الثالث)، ومكتبة واسعة من العمليات عليها، مقدمة من module torch. يمكن استخدام كل tensors وإجراء العمليات المتعلقة بها على وحدة المعالجة المركزية (CPU) أو وحدة معالجة الرسومات (GPU). لا يتطلب نقل العمليات الحسابية من وحدة المعالجة المركزية إلى وحدة معالجة الرسومات في PyTorch أكثر من استدعاء دالة أو اثنتين إضافية .
الشيء الأساسي الثاني الذي توفره PyTorch هو قدرة tensors على تتبع العمليات التي يتم إجراؤها عليها وحساب مشتقات مخرجات الحساب بشكل تحليلي فيما يتعلق بأي من مدخلاته. يتم استخدام هذا التحسين العددي numerical optimization ، ويتم توفيره أصلاً بواسطة tensors عن طريق الإرسال والتوزيع من خلال محرك PyTorch Autograd الموجود في الخلفية.
من خلال وجود Tensors ومكتبة autograd-enabled tensor ، يمكن استخدام PyTorch في الفيزياء والعرض والتحسين والمحاكاة. والنمذجة والمزيد - من المحتمل جدًا أن نرى استخدام PyTorch بطرق إبداعية عبر نطاق واسع من التطبيقات العلمية. لكن PyTorch هي في المقام الأول مكتبة للتعلم العميق، وبالتالي فهي توفر جميع العناصر الأساسية اللازمة لبناء الشبكات العصبية وتدريبها.
يوضح الشكل 1.2 الخطوات العامة لنموذج تعليم عميق
بتحميل البيانات، وتدريب النموذج، ثم نشر هذا النموذج في الإنتاج.
توجد وحدات PyTorch الأساسية لبناء الشبكات العصبية في torch.nn، والتي توفر طبقات الشبكة العصبية المشتركة والمكونات المعمارية الأخرى.
يمكن العثور هنا على الطبقات المتصلة بالكامل، والطبقات التلافيفية convolutional layers ، ووظائف التنشيط activation functions ، ووظائف الخسارة loss functions (سنتناول المزيد من التفاصيل حول ما يعنيه كل ذلك أثناء قراءتنا لبقية هذا الكتاب).
يمكن استخدام هذه المكونات لبناء وتهيئة النموذج غير المدرب الذي نراه في وسط الشكل 1.2.
من أجل تدريب نموذجنا، نحتاج إلى بعض الأشياء الإضافية: مصدر لبيانات التدريب، ومُحسِّن optimizer لتكييف النموذج مع بيانات التدريب، وطريقة لإيصال النموذج والبيانات إلى الأجهزة التي ستقوم بالفعل بإجراء العمليات الحسابية اللازمة لتدريب النموذج.
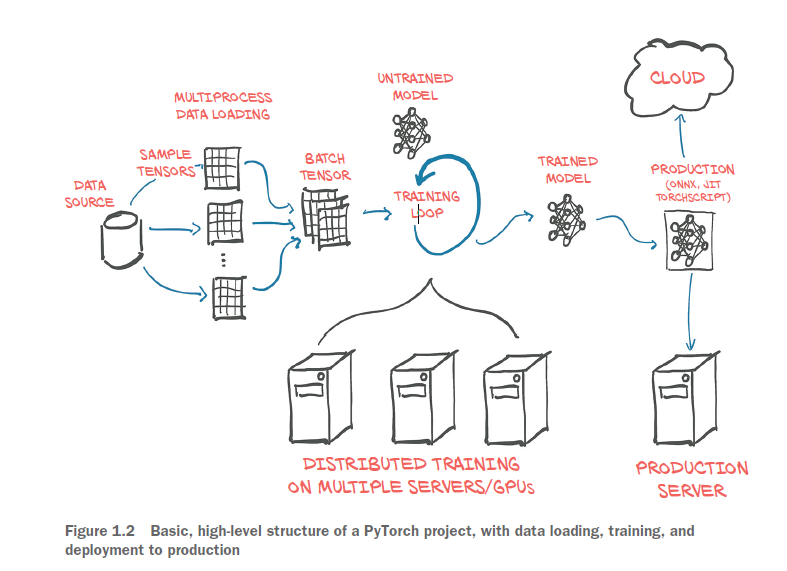
Figure 1.2 Basic, high-level structure of a PyTorch project, with data loading, training, and deployment to production
At left in figure 1.2, we see that quite a bit of data processing is needed before the
training data even reaches our model.4 First we need to physically get the data, most
often from some sort of storage as the data source. Then we need to convert each sample
from our data into a something PyTorch can actually handle: tensors. This bridge
between our custom data (in whatever format it might be) and a standardized
PyTorch tensor is the Dataset class PyTorch provides in torch.utils.data. As this
process is wildly different from one problem to the next, we will have to implement
this data sourcing ourselves. We will look in detail at how to represent various type of
data we might want to work with as tensors in chapter 4.
As data storage is often slow, in particular due to access latency, we want to parallelize
data loading. But as the many things Python is well loved for do not include easy,
efficient, parallel processing, we will need multiple processes to load our data, in order
to assemble them into batches: tensors that encompass several samples. This is rather
elaborate; but as it is also relatively generic, PyTorch readily provides all that magic in
the DataLoader class. Its instances can spawn child processes to load data from a dataset
in the background so that it’s ready and waiting for the training loop as soon as the
loop can use it. We will meet and use Dataset and DataLoader in chapter 7.
With the mechanism for getting batches of samples in place, we can turn to the
training loop itself at the center of figure 1.2. Typically, the training loop is implemented
as a standard Python for loop. In the simplest case, the model runs the
required calculations on the local CPU or a single GPU, and once the training loop
has the data, computation can start immediately. Chances are this will be your basic
setup, too, and it’s the one we’ll assume in this book.
At each step in the training loop, we evaluate our model on the samples we got
from the data loader. We then compare the outputs of our model to the desired output
(the targets) using some criterion or loss function. Just as it offers the components
from which to build our model, PyTorch also has a variety of loss functions at our disposal.
They, too, are provided in torch.nn. After we have compared our actual outputs
to the ideal with the loss functions, we need to push the model a little to move its
outputs to better resemble the target. As mentioned earlier, this is where the PyTorch
autograd engine comes in; but we also need an optimizer doing the updates, and that is
what PyTorch offers us in torch.optim. We will start looking at training loops with loss
functions and optimizers in chapter 5 and then hone our skills in chapters 6 through
8 before embarking on our big project in part 2.
It’s increasingly common to use more elaborate hardware like multiple GPUs or
multiple machines that contribute their resources to training a large model, as seen in
the bottom center of figure 1.2. In those cases, torch.nn.parallel.Distributed-
DataParallel and the torch.distributed submodule can be employed to use the
additional hardware.
The training loop might be the most unexciting yet most time-consuming part of a
deep learning project. At the end of it, we are rewarded with a model whose parameters
have been optimized on our task: the trained model depicted to the right of the
training loop in the figure. Having a model to solve a task is great, but in order for it
to be useful, we must put it where the work is needed. This deployment part of the process,
depicted on the right in figure 1.2, may involve putting the model on a server or
exporting it to load it to a cloud engine, as shown in the figure. Or we might integrate
it with a larger application, or run it on a phone.
One particular step of the deployment exercise can be to export the model. As
mentioned earlier, PyTorch defaults to an immediate execution model (eager mode).
Whenever an instruction involving PyTorch is executed by the Python interpreter, the
corresponding operation is immediately carried out by the underlying C++ or CUDA
implementation. As more instructions operate on tensors, more operations are executed
by the backend implementation.
PyTorch also provides a way to compile models ahead of time through TorchScript.
Using TorchScript, PyTorch can serialize a model into a set of instructions that can be
invoked independently from Python: say, from C++ programs or on mobile devices. We
can think about it as a virtual machine with a limited instruction set, specific to tensor
operations. This allows us to export our model, either as TorchScript to be used with
the PyTorch runtime, or in a standardized format called ONNX. These features are at
the basis of the production deployment capabilities of PyTorch. We’ll cover this in
chapter 15.
1.5 Hardware and software requirements
This book will require coding and running tasks that involve heavy numerical computing,
such as multiplication of large numbers of matrices. As it turns out, running a
pretrained network on new data is within the capabilities of any recent laptop or personal
computer. Even taking a pretrained network and retraining a small portion of it
to specialize it on a new dataset doesn’t necessarily require specialized hardware. You
can follow along with everything we do in part 1 of this book using a standard personal
computer or laptop.
However, we anticipate that completing a full training run for the more advanced
examples in part 2 will require a CUDA-capable GPU. The default parameters used in
part 2 assume a GPU with 8 GB of RAM (we suggest an NVIDIA GTX 1070 or better),
but those can be adjusted if your hardware has less RAM available. To be clear: such
hardware is not mandatory if you’re willing to wait, but running on a GPU cuts training
time by at least an order of magnitude (and usually it’s 40–50x faster). Taken individually,
the operations required to compute parameter updates are fast (from
fractions of a second to a few seconds) on modern hardware like a typical laptop CPU.
The issue is that training involves running these operations over and over, many, many
times, incrementally updating the network parameters to minimize the training error.
Moderately large networks can take hours to days to train from scratch on large,
real-world datasets on workstations equipped with a good GPU. That time can be
reduced by using multiple GPUs on the same machine, and even further on clusters
of machines equipped with multiple GPUs. These setups are less prohibitive to access
than it sounds, thanks to the offerings of cloud computing providers. DAWNBench
(https://dawn.cs.stanford.edu/benchmark/index.html) is an interesting initiative
from Stanford University aimed at providing benchmarks on training time and cloud
computing costs related to common deep learning tasks on publicly available datasets.
So, if there’s a GPU around by the time you reach part 2, then great. Otherwise, we
suggest checking out the offerings from the various cloud platforms, many of which offer
GPU-enabled Jupyter Notebooks with PyTorch preinstalled, often with a free quota. Google
Colaboratory (https://colab.research.google.com) is a great place to start.
The last consideration is the operating system (OS). PyTorch has supported Linux
and macOS from its first release, and it gained Windows support in 2018. Since current
Apple laptops do not include GPUs that support CUDA, the precompiled macOS
packages for PyTorch are CPU-only. Throughout the book, we will try to avoid assuming
you are running a particular OS, although some of the scripts in part 2 are shown
as if running from a Bash prompt under Linux. Those scripts’ command lines should
convert to a Windows-compatible form readily. For convenience, code will be listed as
if running from a Jupyter Notebook when possible.
For installation information, please see the Get Started guide on the official
PyTorch website (https://pytorch.org/get-started/locally). We suggest that Windows
users install with Anaconda or Miniconda (https://www.anaconda.com/distribution
or https://docs.conda.io/en/latest/miniconda.html). Other operating systems like
Linux typically have a wider variety of workable options, with Pip being the most common
package manager for Python. We provide a requirements.txt file that pip can use
to install dependencies. Of course, experienced users are free to install packages in
the way that is most compatible with your preferred development environment.
Part 2 has some nontrivial download bandwidth and disk space requirements as
well. The raw data needed for the cancer-detection project in part 2 is about 60 GB to
download, and when uncompressed it requires about 120 GB of space. The compressed
data can be removed after decompressing it. In addition, due to caching some
of the data for performance reasons, another 80 GB will be needed while training.
You will need a total of 200 GB (at minimum) of free disk space on the system that will
be used for training. While it is possible to use network storage for this, there might be
training speed penalties if the network access is slower than local disk. Preferably you
will have space on a local SSD to store the data for fast retrieval.
1.5.1 Using Jupyter Notebooks
We’re going to assume you’ve installed PyTorch and the other dependencies and have
verified that things are working. Earlier we touched on the possibilities for following
along with the code in the book. We are going to be making heavy use of Jupyter Notebooks
for our example code. A Jupyter Notebook shows itself as a page in the browser
through which we can run code interactively. The code is evaluated by a kernel, a process
running on a server that is ready to receive code to execute and send back the results,
which are then rendered inline on the page. A notebook maintains the state of the kernel,
like variables defined during the evaluation of code, in memory until it is terminated
or restarted. The fundamental unit with which we interact with a notebook is a
cell: a box on the page where we can type code and have the kernel evaluate it (through
the menu item or by pressing Shift-Enter). We can add multiple cells in a notebook, and
the new cells will see the variables we created in the earlier cells. The value returned by
the last line of a cell will be printed right below the cell after execution, and the same
goes for plots. By mixing source code, results of evaluations, and Markdown-formatted
text cells, we can generate beautiful interactive documents. You can read everything
about Jupyter Notebooks on the project website (https://jupyter.org).
At this point, you need to start the notebook server from the root directory of the
code checkout from GitHub. How exactly starting the server looks depends on the
details of your OS and how and where you installed Jupyter. If you have questions, feel
free to ask on the book’s forum.5 Once started, your default browser will pop up,
showing a list of local notebook files.
NOTE Jupyter Notebooks are a powerful tool for expressing and investigating
ideas through code. While we think that they make for a good fit for our use
case with this book, they’re not for everyone. We would argue that it’s important
to focus on removing friction and minimizing cognitive overhead, and
that’s going to be different for everyone. Use what you like during your experimentation
with PyTorch.
Full working code for all listings from the book can be found at the book’s website
(www.manning.com/books/deep-learning-with-pytorch) and in our repository on
GitHub (https://github.com/deep-learning-with-pytorch/dlwpt-code).
1.6 Exercises
1- Start Python to get an interactive prompt.
a What Python version are you using? We hope it is at least 3.6!
b Can you import torch? What version of PyTorch do you get?
c What is the result of torch.cuda.is_available()? Does it match your
expectation based on the hardware you’re using?
2 -Start the Jupyter notebook server.
a What version of Python is Jupyter using?
b Is the location of the torch library used by Jupyter the same as the one you
imported from the interactive prompt?
1.7 ملخص الفصل
- تتعلم نماذج التعلم العميق تلقائيًا ربط المدخلات والمخرجات المطلوبة من الأمثلة.
- تسمح لك مكتبات مثل PyTorch ببناء نماذج الشبكة العصبية وتدريبها بكفاءة.
- يعمل PyTorch على تقليل العبء المعرفي مع التركيز على المرونة والسرعة. كما أنه يعمل افتراضيًا على التنفيذ الفوري للعمليات.
- يسمح لنا TorchScript بترجمة النماذج مسبقًا واستدعائها ليس فقط من Python ولكن أيضًا من برامج C++ وعلى الأجهزة المحمولة.
- منذ إصدار PyTorch في أوائل عام 2017، تم تعزيز النظام البيئي لأدوات التعلم العميق بشكل كبير.
- يوفر PyTorch عددًا من المكتبات المساعدة لتسهيل مشاريع التعلم العميق.
العودة إلي Deep Learning with PyTorch